

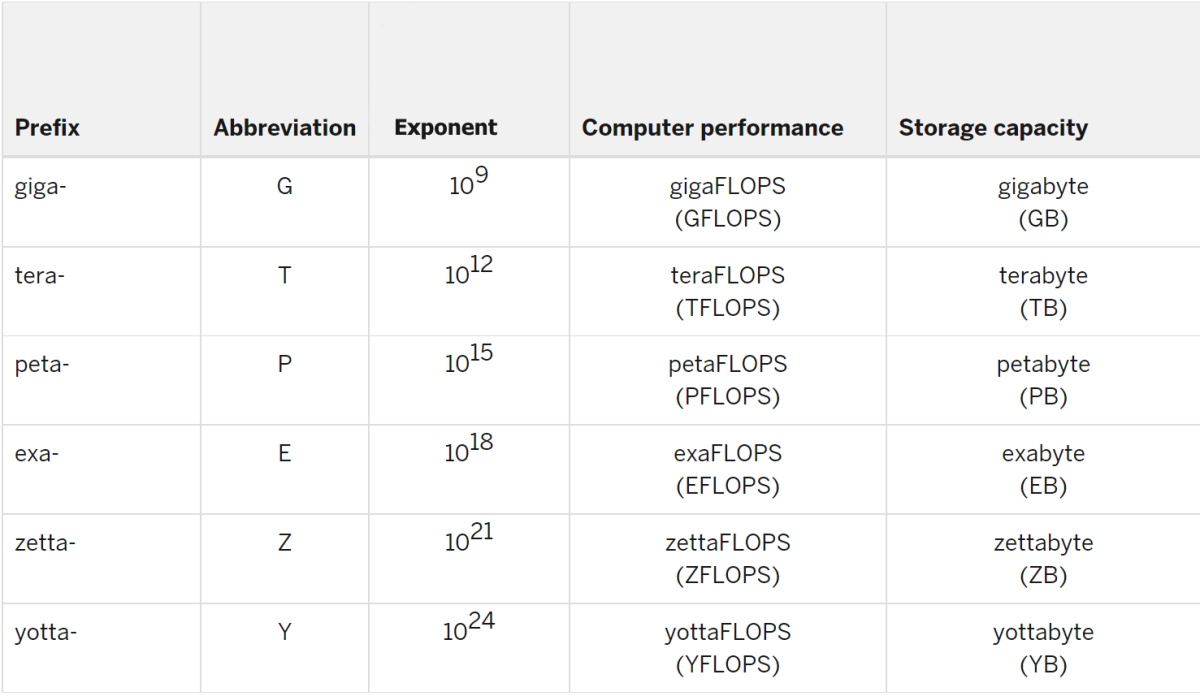
Um exaflop é uma medida de desempenho para um supercomputador que pode calcular pelo menos 1018 ou um quintilhão de operações de ponto flutuante por segundo.
Em exaflop, o prefixo “exa” significa um quintilhão, que é um bilhão bilhão, ou um seguido por 18 zeros. Da mesma forma, um exabyte é um subsistema de memória com um quintilhão de bytes de dados.
O “flop” em exaflop é uma abreviação para operações de ponto flutuante. A taxa na qual um sistema executa um flop em segundos é medida em exaflop/s.
O ponto flutuante refere-se a cálculos feitos em que todos os números são expressos com pontos decimais.
1.000 Petaflops = um Exaflop
O prefixo “peta” significa 1015, ou um com 15 zeros atrás. Então, um exaflop é mil petaflops.
Para entendermos como o cálculo de exaflop é complexo, imagine um bilhão de pessoas, cada uma segurando um bilhão de calculadoras. (Claramente, elas têm as mãos grandes!)
Se todas apertassem o mesmo sinal ao mesmo tempo, executariam um exaflop.
A Universidade de Indiana, lar do Big Red 200 e de vários outros supercomputadores, explica desta forma: para combinar o que um computador exaflop pode fazer em apenas um segundo, você teria que fazer um cálculo a cada segundo por 31.688.765.000 anos.
Uma Breve História do Exaflop
Durante a maior parte da história da supercomputação, um flop foi um flop, uma realidade que está se transformando à medida que as cargas de trabalho incorporam a AI.
As pessoas usaram números expressos no mais alto de vários formatos de precisão, chamados de precisão dupla, conforme definido pelo Padrão IEEE para Aritmética de Pontos Flutuantes. O nome “precisão dupla”, ou FP64, vem do fato de cada número em um cálculo exigir 64 bits, pedaços de dados expressos como zero ou um. Em contrapartida, a precisão única usa 32 bits.
A precisão dupla usa esses 64 bits para garantir que cada número seja preciso em uma pequena fração. É como dizer 1,0001 + 1,0001 = 2,0002, em vez de 1 + 1 = 2.
O formato combina muito bem com a maioria das cargas de trabalho da época: simulações de tudo, de átomos a aviões, que precisam garantir que seus resultados cheguem próximos ao que representam no mundo real.
Então, era natural que o benchmark LINPACK, também conhecido como HPL, que mede o desempenho na matemática FP64 se tornasse a medida padrão em 1993, quando a lista TOP500 dos supercomputadores mais poderosos do mundo foi publicada.
O Big Bang da AI
Há uma década, o setor de computação ouviu o que o CEO da NVIDIA, Jensen Huang, descreve como o big bang da AI.
Essa nova e potente forma de computação começou a mostrar resultados significativos em aplicações científicas e empresariais. Além disso, ela aproveita alguns métodos matemáticos muito diferentes.
Deep learning não se trata de simular objetos do mundo real, mas sim de examinar montanhas de dados para encontrar padrões que possibilitem novos insights.
Sua matemática exige alta taxa de processamento. Por isso, fazer muitos, muitos cálculos com números simplificados (como 1,01 em vez de 1,0001) é muito melhor do que fazer menos cálculos com os números mais complexos.
É por isso que a AI usa formatos de precisão mais baixa, como FP32, FP16 e FP8. Seus números de 32, 16 e 8 bits permitem que os usuários façam mais cálculos mais rapidamente.
A Precisão Mista Evolui
Para AI, usar números de 64 bits seria como usar todas as suas roupas de uma vez ao sair no fim de semana.
Encontrar a técnica ideal de precisão mais baixa para AI é uma área ativa de pesquisa.
Por exemplo, a primeira GPU NVIDIA Tensor Core, a Volta, usou precisão mista. Executou a multiplicação de matrizes em FP16 e, em seguida, acumulou os resultados em FP32 para obter maior precisão.
Hopper Acelera com FP8
Mais recentemente, a arquitetura NVIDIA Hopper estreou com um método de precisão mais baixa para treinamento de AI que é ainda mais rápido. O Engine Transformer da Hopper analisa automaticamente uma carga de trabalho, adota FP8 sempre que possível e acumula resultados em FP32.
Quando se trata da tarefa de inferência com menos uso intensivo de computação, executar modelos de AI em produção, grandes frameworks, como TensorFlow e PyTorch, são compatíveis com números de inteiros de 8 bits para obter desempenho rápido. Isso é porque eles não precisam de pontos decimais para fazer seu trabalho.
A boa notícia é que as GPUs NVIDIA são compatíveis com todos os formatos de precisão (acima), para que os usuários possam acelerar todas as cargas de trabalho da maneira ideal.
No ano passado, o comitê do IEEE P3109 começou a trabalhar em um padrão do setor para formatos de precisão usados em machine learning. Esse trabalho pode levar mais um ano ou dois.
Nenhum comentário:
Postar um comentário